Jeetu Kumar Gupta1*, Sohit Agarwal2
1Department of Computer Engineering and Information Technology, Suresh Gyan Vihar University, India
e-mail: kalwar.gupta@gmail.com, sohit.agarwal@mygyanvihar.com
Abstract: Natural Language Processing is the area of Computer Science and the Artificial Intelligence. NLP is used for the communication with human and machines in natural language. Natural Language Processing is widely used and is the topic of research. Previously decade ago NLP was only used for the knowledge representation, constraint satisfaction and logical reasoning, where the text first applied to semantic and then to grammar. But now a days NLP has gain focus towards it because of its applications in the field of machine learning and data mining. It has made changes in the learning rate and methods of Artificial Intelligence and Neural Network. NLP has basic goal of understanding the text that what it means and generate the response after analyzing the text. NLP can be processed in two forms, by speech and by text. Major application of NLP is Machine Translation, Text Processing and Speech Recognition. In this paper we give an overview of Natural Language Processing, how it works, its usages in different sectors, and the algorithms used in it.
Keywords: NLP, AI, Data mining, Machine Learning, Neural Network, Chatbot
- Introduction
Natural Language Processing can make machines (computers) understand human language or simply we can say that, NLP makes the humans to have conversation with machines. NLP has powers to enable the machines to understand the human language and generate response in human language. Application of NLP is widely used in various sectors like Virtual Assistant where the most advanced products are Siri from Apple, Alexa from Amazon and Ok Google from Google, but there are also things like Data mining and Machine Translation. Natural Language Processing came in focus when the advancement in the technology like machine learning and especially in the Deep Learning Techniques [1].
Machine learning is the technology which is the part of Artificial Intelligent which is used to make the machine, intelligent. Whereas Neural Network and Deep Learning is the subset of Machine Learning as it helps in increasing the accuracy, as it iterates again and again for the data sets through algorithms.
NLP is basically divided into two following parts: –
Natural Language Understanding: – NLU is the part of NLP which has the ability to make computers understand the meaning of the text.
Natural Language Generation: –NLG is the part of NLP which generate the response after analyzing the text’s meaning in natural language.
NLP is so important in coming future because it is useful in making models and process it, where it takes the raw input data in text and speech or in both form and manipulate the input with algorithms and produce outputs.
There are different algorithms which can increase the efficiency of processing of the language in the text form, are as follows: –
- Long Short Term Memory
- Sequence 2 Sequence Model
- Named Entity Recognition Model
- User Preference Graph Model
- Word Embedding model
Also there are different algorithms which are used for processing the natural language in voice form are as follow:
- Word Recognition
- Acoustic Modeling
- Connectionist temporal classification
- Phased based machine translation
- Neural machine Translation
- Google neural machine translation
In this paper we are going to discuss about the algorithms mentioned above about what are they and how they are helpful in processing the text.
- Algorithms and Models
LSTM
LSTM is abbreviated as Long Short Term Memory. LSTM is the extended version of RNN (Recurrent Neural Network). RNN is the chunk of Neural Network which has internal memory that gives ability to remember values. It can remember the previous values which are given as inputs. Through input values it is used for training machine. LSTM is broadly used in the Natural Language Processing for learning model in Machine Learning.
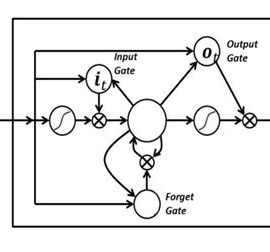
Fig: – LSTM [2]
Input Gate,Forget Gate and Output Gate.
LSTM has Gates as Input Gate, Forget Gate and Output, which are able to read the value, modify the value and delete the value. In LSTM the input value is never changed. Gates can open and close as to forget and remember the inputs, we can also say “0” as to forget the value and “1” as to keep the value. After that there is tanh layer which creates the vector of new values which is combined to input values and give the updated value as output.
Sequence 2 Sequence Model
Seq2Seq model is used for training the machine for Question and Answer bases types. In this model there are two Recurrent Neural Network of most Probably LSTM consisting internal memory to store previous inputs which can be helpful for giving reply according to the inputs.
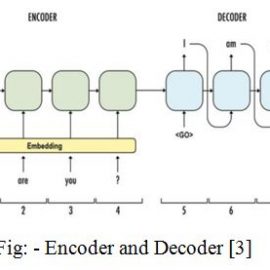
Fig: – Encoder and Decoder [3]
In this model the inputs are encoded by encoder and the output is decoded by decoder. There is a list called vocabulary list which contains the frequently used, rarely used and unique words in the sentence. This list is used for the correct grammar syntax and assemble the words in order in sentence. Then after the sentence is assemble the words are replaced with ids. According to the input the reply is being suggested and decoded for the output, based on the id’s.
- Named Entity Recognition Model
In this model Name Entity Recognition is used to classify the names of the words/entity, into categories like Person name, company name, location name, quantities name, movie name etc. after analyzing the text.
E.g. OnePlus(company) to launch OnePlus 7(product) in 10 may (date)
In NER model works on two different ways. The very first way is process to divide the text into segments also called chunks, which is used to classify into the categories of person, place, product, organization [4]. Second phase model are used for processing in language and speech where User Performance graph is used to give smart reply in search suggestion
- User Preference Graph Model
User Preference Graph is a model which is designed according to the user’s behavior of writing or giving the input. The model recognizes the behavior of giving inputs of specific tenses, adjectives, conjunction and prepositions etc. After that the model prepares a list for frequently used words after the specific word and map it according to the probability. In future the user tries to give input or write something then the suggestion will be given to the user for next word according to the trained model. This model is being used in smart reply, suggestions in typing, and reply system. This model helps the user in saving time and increasing the efficiency.
- Word Embedding Model
Word Embedding is the feature learning and language modeling, which the words and phrases are converted into numerical format at high dimensional space. This technique can convert the character, word, document as vector. This technique is also known as state of the art.
E.g.
- Application of NLP
- Machine Translation: – Machine Translation isthe automatic process to translate the text from one natural language (English) to another natural language (Hindi). To translate the source and target natural language is not an easy task as by translating word by word, the machine has to process the translation according to the elements presents in the text and what the other word has degree towards the other element. This process requires heavy computation power and the knowledge of grammar, syntax, semantics (meaning) which NLP can do with the help of Machine Learning and Deep Neural Networks [5]. This is helpful in reducing the language barrier in different countries, international conference and many more sectors.
- Sentiment Analysis: – It is the process of opinion mining from the unstructured data sources like social media. It generates the structured data to find the opinion from the person’s responses, feedback generated in form of unstructured data. It gives the polarity of the topic whether the topic is taken as positive, negative or neutral. This can be done through NLP with the help machine learning and deep learning for efficiency. This process is very powerful and useful in many sectors like advertisements, movie review, products feedback.
- Information Retrieval: – It is the process of retrieval of relevant information from the text or document according to the needs. It is like searching a specific topic from the documents. This process is done with the help of tokens matching according to the context. E.g. Search engine like Google search, Bing, Yahoo [6].
- Text Categorization: – It is the process of categorization of text and sorting the text in order in the syntax of sentence.
- Extracting data: – This is the process to access the unstructured data and extracting the information to the structured form as per the requirements. Extracting data from unstructured data is a mess and require NLP for cleansing and processing the data to structured form. These are helpful in extracting the data from unstructured data sources like social media, and match the data according to the context. Helpful in sectors like Business, Marketing, Advertisements and many more [7].
- Spellings and Grammars: – This is the process to take the text as input and do the preprocessing like tokenization for correcting the spelling mistake and grammar of the context. This is helpful for content creators, and many sectors.
E.g. Shcool à School (Spelling)
E.g. Ravi is going to home.
Ravi is going home. (Grammar)
- Text Pre-processing
- Tokenization: – Tokenization is the process of breaking down the text into sentence and words. These breaks downs are known as tokens, these can be words, numbers and punctuation [8].
E.g. “Rahul”, “ate”, “mangos”.
- Stemming: – Stemming is the process of breaking down the affixes of the tokens, and convert the word in meaningless word.
E.g. move, moving, moved à mov
- Lemmatization: – It is the process of converting the tokens in meaningful word as simple root word.
E.g. moving, moved, moves à move.
- Stop words: – stop words are the words or tokens which has very less or no importance to the sentence. So it is the process to remove the stop words.
E.g. “He has beautiful car in his garage”
Output à“beautiful car garage”
- Bag of word: – It is the process of counting the number of tokens occurred in the text, and stored in the list.
E.g. “He has car and he has bike in his garage”.
Output à He = 2, has = 2, car = 1 etc.
- POS Tagging: – This is the process to tag the tokens of the sentence, this process are used to determine that the tokens are either noun, pronoun, verb, adverb, determiner, adjective etc. E.g. [(word, tag), (word, tag)].
- Process of NLU
- Raw Speech Signal: – The process of receiving raw input as speech from the microphone, then the input is in Analog signal which is then converted into Frequency spectrogram in digital form. Now it analyzes the sound (“a”, “th” …) and helps in constructing the words from phonemes (“th”, “I”, “ng” = “thing”).
Here we do have the complication in analyzing the word as the sound or pronunciation may be similar but the word and meaning is different. E.g. bear, bare, beer. With these complications we have gaps between the words and can change the whole sentence.
E.g. “how to recognize speech”
“how to wreck a nice beach”
This may happen due to the noise in the background.
- Syntactic Analysis: – It is the process of arranging the words in sentence with rule of syntax (grammar), which allows to determine the sentence’s structure.
E.g. Ravi love Seema.
Love (Ravi, Seema)
Then it parses the given sentence with grammar after checking the sentence is correct and return the parse tree as structure of sentence.

In syntactic analysis we have complication as to identify whether the word is singular or plural or it have problem to identify the gender. In this analysis we also have the major complication of handling the ambiguity which has more than one possible meaning of the sentence.
E.g. “The chicken is ready to eat.”
Here is the chicken hungry to eat something or chicken itself is being prepared as food to eat.
- Semantic Analysis: – Semantic analysis is used to analyze the words meaning which is being used to represent the sentence from the syntactic structure. It has complication of having different or multiple meaning with same word in the sentence. E.g. “play guitar”, “play a song”, “play a role”, “play a game”. Here play word has different meaning according to context [9]. A person never knowswhat to do according to word play, if he has guitar and music player and he receive a command to play a song.
- Pragmatic Analysis: – In this analysis it makes the context of sentence, where it handles the intensions for what and to whom it is supposed to be mean, like promise, request, inform and also where, by who, when. It also handles the pronouns in the sentence
E.g. “John goes to school. He likes to study there.”
He è “John”, there è “school”.
It also helps in handling the ambiguity of the sentence according to the context.
E.g. “The police are coming.”
Are the police are coming for you as if any incident happens nearby or they are just coming for patrolling.
- Conclusion
Natural Language Processingwith high computational power and technologies like Machine Learning and Deep Neural Network have made the text processing easy efficient and more efficient in many tools like chatbot. Speech processing problems are also somewhat solved and being more reliable to the text processing problems. These applications are used in many areas like business sectors, analysis of data for product, marketing, sales, advertisements. Though many problems are pending like cognitive, emotions, incentives and skills, also the data availability is important in analyzing. Various AI techniques are involved in resolving the problems of text processing and speech processing algorithms that classifying the inputs for user’s requirements and personalized according to the needs.
References:
- J K Gupta and S Agarwal ― An Epitome of Chatbot: A Review Paper Vol.-7, Issue-1, Jan 2019
- Rohan & Lenny #3: Recurrent Neural Networks & LSTMs Apr 13, 2017 [online] https://ayearofai.com/rohan-lenny-3-recurrent-neural-networks-10300100899b
- The 7 NLP Techniques That Will Change How You Communicate in the Future (Part I), June 2018 [online] https://mc.ai/the-7-nlp-techniques-that-will-change-how-you-communicate-in-the-future-part-i/
- Susan Li, Named Entity Recognition with NLTK and SpaCy, Aug 17, 2018 [online] https://towardsdatascience.com/named-entity-recognition-with-nltk-and-spacy-8c4a7d88e7da
- Grégoire Mesnil, Yann Dauphin et al. “Using Recurrent Neural Networks for Slot Filling in Spoken Language Understanding” IEEE Press Piscataway, NJ, USA Volume 23 Issue 3, March 2015.
- Prashant G Desai, Saroja “A Study of Natural Language Processing Based Algorithms for Text Summarization” Devi Niranjan N Chiplunkar, Mahesh Kini M.
- Pratulya Bubna, Shivam Sharma, Sanjay Kumar Malik, “Linking Online News Semantically Using NLP and Semantic Web Technologies”, July 2018
- Alghamdi, and K. Alfalqi. “A Survey of Topic Modeling in Text Mining” International Journal of Advanced Computer Science and Applications Vol. 6, pp. 147-153, 2015.
- Nanda, M. Dua, “A Survey on Sentiment Analysis”, International Journal of Scientific Research in Computer Science and Engineering, Vol. 5, Issue. 2, pp. 67-70, 2017.