Nitish Rasgotra
Research Scholar
Center for cloud infrastructure and security
Suresh Gyan Vihar University, Jaipur
rnitish705@gmail.com
Sohit Agarwal
Assistant Professor
Dept. of Computer Science
Suresh Gyan Vihar University, Jaipur
sohit.agarwal@mygyanvihar.com
Abstract— As a biometric department, facial recognition focuses on recognizing their faces by focusing on different facial features and identifying each facial feature in their facial recognition. One of the main application technologies today is face recognition technology that uses a set of photos and special photos. Although single-image facial recognition technology is relatively mature, it has some drawbacks. In this document, the Honda / USCD video database is used to compare and analyze two technologies, and the accuracy of facial recognition methods based on spatial binary sampling (LBP) is examined. The results show that face recognition technology that uses image sets has a good understanding of detection and can be well implemented to identify smart customers, control access control systems, vehicle access systems, smart security and identity.
Keywords— Face Recognition, face recognition, image sets, intelligent shopping, local binary patterns (LBPs) Feature Extraction Accuracy, Performance, RF, SVM.
I. INTRODUCTION
As a biometric section, face recognition focuses on facial features and distinguishes each page by recognizing their faces. 1 Two-page recognition technology is currently available: one using a photo and one using a photo set. Recent appearances have expanded the field of improved recognition functionality and face recognition.
The use of single images is a common facial recognition technology that has been widely used for extraction, feature fusion, classification design and multiclassifier communication, and has practical applications in real life. And in the last few years, business has become an attraction for both because of friendship and convenience. However, there are still some shortcomings in dealing with identity technology using images, the most serious of which is identity accuracy. Depending on the quality of the image and the quality of the image, it will decrease by several factors. In particular, because of the change of personal posture and expression, certain facial features, age changes and relatively low quality of speech will reduce recognition accuracy, so photo seat recognition technology is the place of best application. At the same time, in limited cases with facial images, many previous studies can yield satisfactory submission rates. However, for practical recognition that facial recognition is used, several irregular factors arise, such as presence, pose variation, complex background as well as illumination variations that are truly normal and unavoidable. Therefore, this technology cannot guarantee good results in most practical applications. The video cannot be controlled arbitrarily. On the other hand, face recognition technology using photo sets is stronger and more efficient, more robust and efficient than face recognition technology using single image, which extends the application of facial recognition. In many applications, such as using a different camera for face tracking or comparison, the use of photo-seat technology is very useful.
Face recognition is also very important in science and technology, which not only meets the evolving needs of artificial intelligence (AI), but also helps you better understand your vision system. The reflection of facial recognition development has recently been reflected in the area of strong AI and will lead to technological advancements in other areas such as specialist systems, video image processing and machine learning. Therefore, we can conclude that it offers facial recognition. The development of facial recognition technology using brighter futuristic photo sets has expanded the spectrum of facial recognition applications to include video image applications. In addition, the development and model recognition of machine learning will benefit from this.
It has made sense to transfer information from things that are on the internet through Internet-based things. Today, the Internet of Things and data environments are getting more complex, and systems and infrastructure Internet solutions based on big data are becoming more difficult. Page recognition is a way to use and solve the Internet and big data problems. Face recognition provides people with a smart experience of identifying algorithms specific to formulas, border breaks and face-to-face features. The Internet of Things is a face recognition platform and facial recognition is the smart identification method of the Internet of Things sensor network. The two complement each other to enhance the Internet of Things development.
An effective and practical algorithm is proposed in this article to counteract the negative effects imposed by luminescence in the facial recognition process. The method of face detection is to study, detect and practice facial imagery. Secondly, the algorithm of characterizing the local binary model feature is studied, and its properties and algorithms are studied. Later, the local binary model (LBP) B feature algorithm was applied to the image feature information and the image was set to improve the identification rate of the algorithm. Finally, the LBP-based face image set recognition algorithm is studied, and the method of modulating the phonetic packet and the optimization of some parameters are studied in detail.
II. OVERVIEW OF FACE RECOGNITION AND RELEVANT ALGORITHMS
LBP refers to the local binary state, which initially acts as the local contrast of the supporting image. The Internet of Things (IoT) is the rise of the Internet to make people object. With the development of the community and the widespread need for artificial intelligence, Internet technology has gradually transformed into the Internet of Things and is widely used in practice, a major trend. The use of facial recognition technology in IoT is a relatively cutting edge technology. The combination of the two technologies is also the basis of the photo-seat face recognition technology. Therefore, this study is based on the above trends.
Facial recognition research began in the 1960s and has made great strides since then. Facial recognition, as one of the best and most important tasks in computer vision, is commonly used in video distribution and pediatric tracking as delivery diagnostics and home healthcare 9 are the basic algorithms of facial recognition technology, which determine accuracy and speed. Identify. Presently, Island Science and Technology, Guangzhou South Wine Science and Technology Information Company, Ltd., Biology Faculty of the University of Science and Technology, MyPu Science and Technology, Alibaba and other companies are at the forefront of technology. Some of the results of their application can not only be applied to mobile phones, smart lock and other aspects but also cooperate with public safety companies and get good results. It turns out that face recognition technology is very important not only in theory but also in practice. The concept of facial recognition is to distinguish different individuals by comparing the image of the image identified with the labeled images. With things like angle changes, brightness changes, appearance and position changes, noise, low resolution, object appearance, and a few single-class patterns including multiple sections (mm), facial recognition is still his. Yet progress is a challenge. Currently, facial recognition studies are theoretically comparatively complete, and it is expected that facial recognition will improve with practical application and more effort.
As for facial recognition behavior, the above algorithms are featured and thus suitable for different situations. Considering their advantages and disadvantages, many algorithms can be integrated to achieve high recognition accuracy in many practical cases. 12 Although facial recognition technology for the use of images has grown relatively large and has seen a comparatively broad field with many years of study, shooting changes, R&A, and post and expressions can reduce recognition accuracy. This is difficult to pinpoint. As an alternative technology that can avoid this problem, facial recognition technology using image sets has attracted more attention over the years. This technology can combine techniques created for anything, such as using multiple images such as multilayer and spreadsheet. In addition, the two technologies can be integrated to achieve better recognition performance.
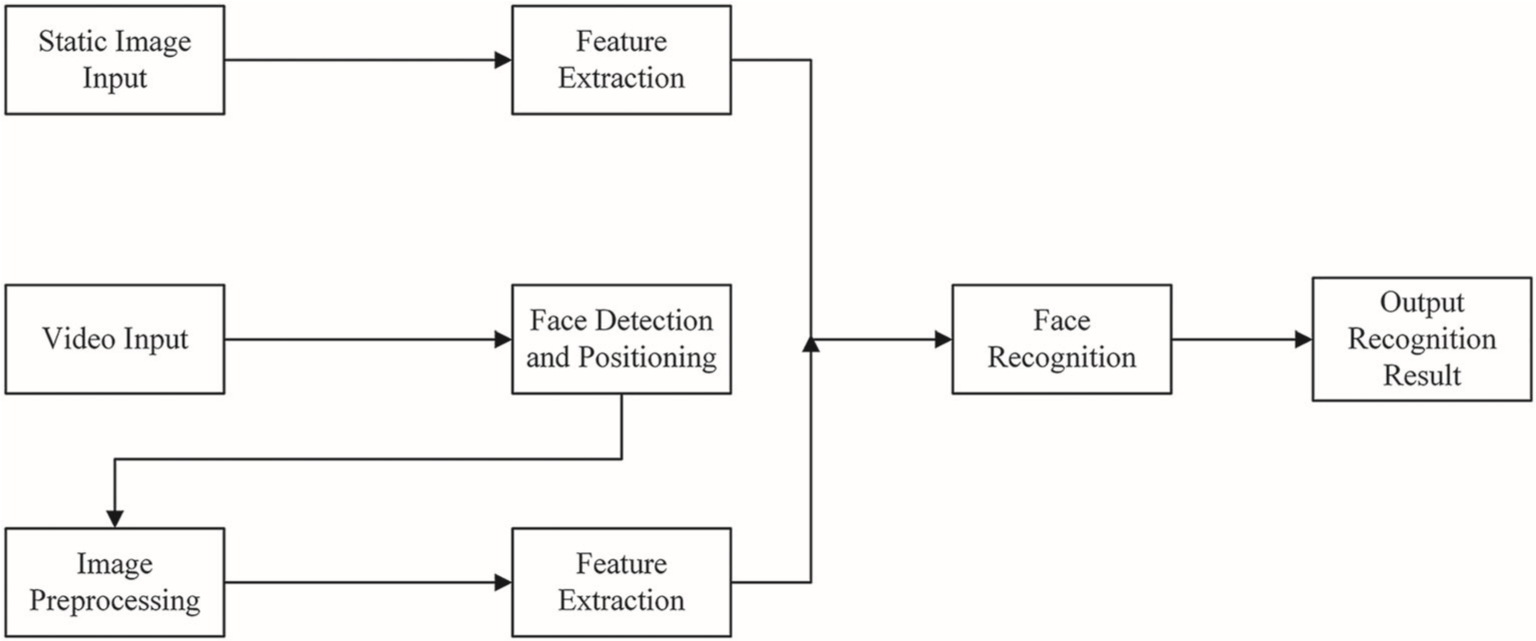
Figure 1 The basic process of face recognition
- Process for face recognition
As shown in Figure 1, facial recognition consists of four steps: First, collect and find facial images; Second, prepare them; Third, remove features from these; And fourth, mill and identify them.
Image collection and exploration decided whether the pages were available at the given image or video level. If an object is found in the image, it must be located and the relevant parts of the image must be extracted. If a face is detected during a video, it should be tracked by the mouth, such as the nose, eyes, mouth and face shape. In this article, the page photos will be retrieved from the Honda / UCSD video database.
Image preprocessing, whose main purpose is to eliminate disasters, remove words and include blurry images. Providing an image in facial recognition is much easier than using a single image or even skipping, because an image set contains a lot of information and, although it is useful information, a person’s image can be described as effectively long information is generally considered. Thus, the effect of confusion on photo sets is minimal or even non-existent.
Feature extraction, which means collecting small amounts of useful data from this national primary data to represent the face, is one way to reduce computation costs. A person relies on multiple images in face recognition technology using a photo set, so each image has its features. Feature extraction can significantly reduce the cost of detection without reducing the accuracy of detection.
Comparing and identifying images means that the targeted page is compared to the inactive B attribute, and that the properties labeled B in the database are compared to the B attribute, and which page in the database is labeled B. The face matches the same degree. For facial recognition using a photo set, the degree of matching corresponds to the distance between the two photo sets.
Facial recognition algorithms make it difficult to obtain models with high recognition accuracy without employing a small number of training modules for a single class before learning. The number of pages per person is relatively low in the current public page sample data. Training a good network model without sufficient information is difficult for deep learning. The accuracy of facial recognition depends largely on feature extraction algorithms and similar algorithms. As a result, databases play an important role in training the best network model. As shown in Figure 2, the above four steps are also necessary and important for facial recognition using the photo sets studied in this image. An additional episode of modeling is the image set, which is an important challenge point.
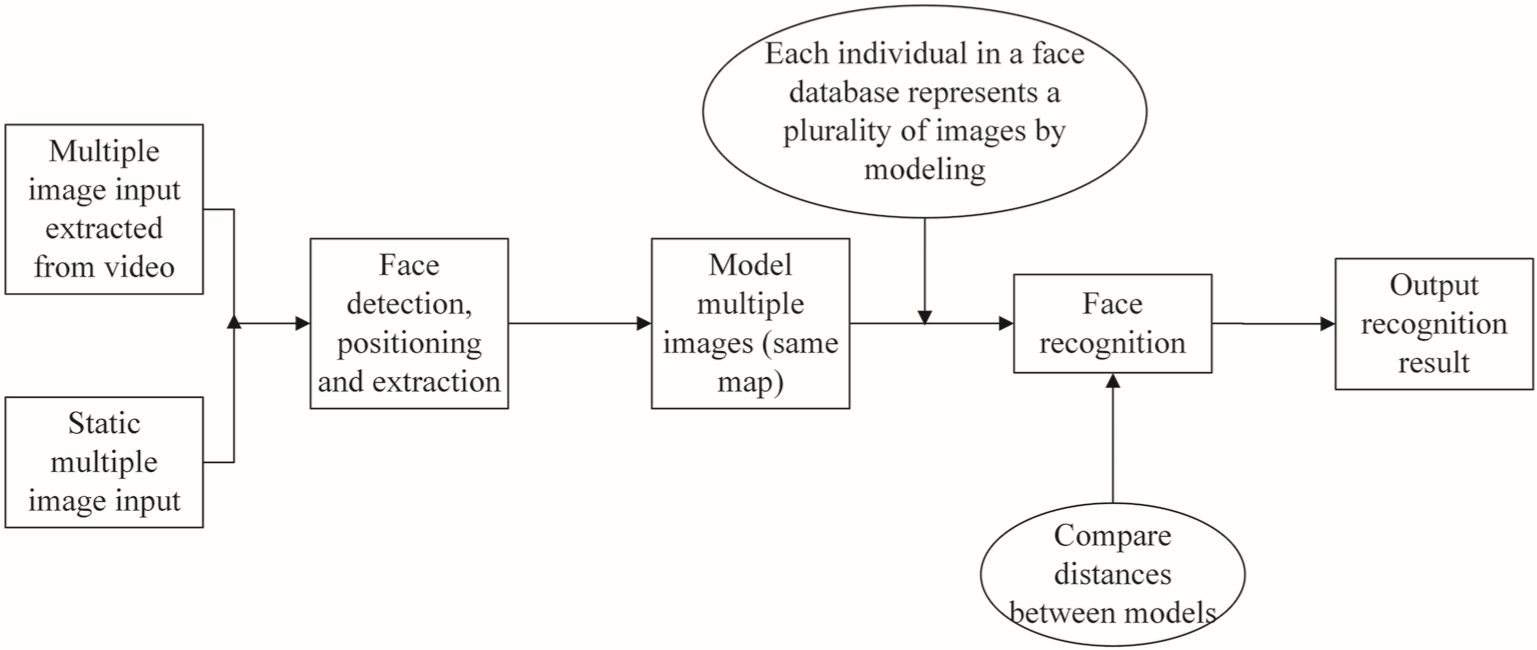
Figure 2 The basic process of face recognition based on image sets.
- Face Detection (The Viola Jones algorithm)
A number of classical algorithms have been proposed, including decades of studies on face detection. Of all the algorithms, Viola and Jones proposed to him in 2001, it is based on the Ada Boost algorithm, characterized by its good performance and relatively high speed, and thus it is widely used at the currently available level.
The Viola-Jones algorithm is bifurcated by a hard core, weak and strong classification and a cascade classification. Second, calculate the Harlequick B properties values with an integrated image view; Third, training the recipient of the weaker category using the Adjust algorithm, and classifying the others in the weaker sections fill in the margin. Get strong class recipients with it; And fourth, combine strong classifiers to create a cascade category, which has relatively high detection efficiency.
In short, the goal of the Viola Jones-Jones algorithm is to obtain a cascade category based on a set of training sets, which can identify images precisely and quickly. The process of teaching the classrooms is shown in Figure 3.
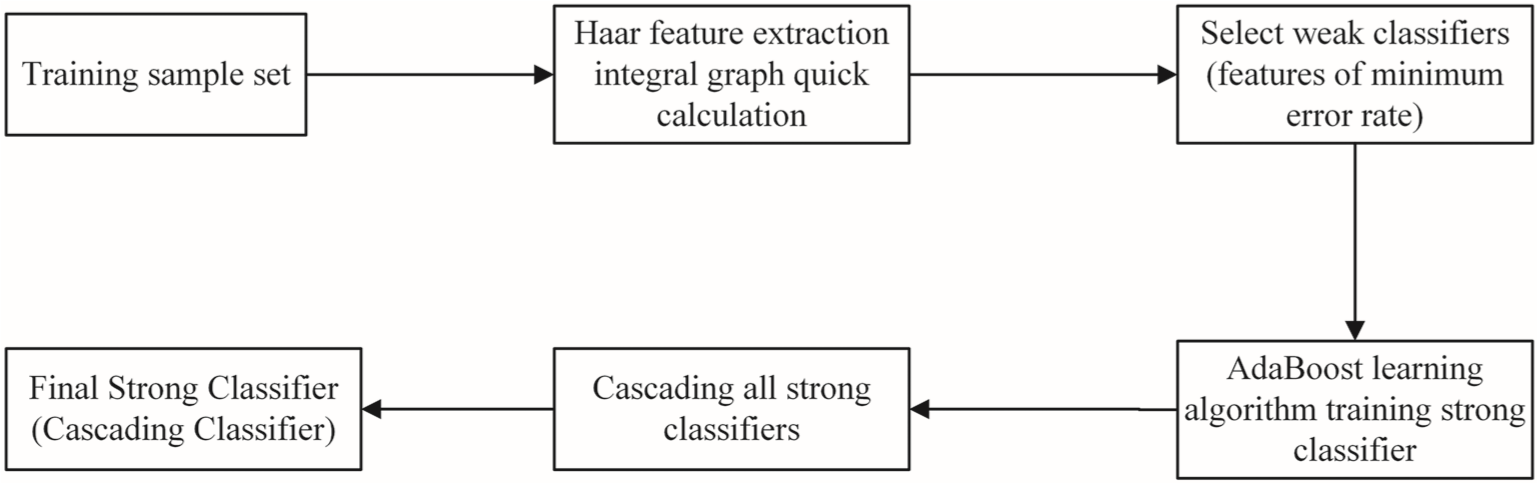
Figure 3 Classifier training process
- Haar features/rectangle features
In the Viola-Jones algorithm, the inserted images are represented by the same feature as the Harrer-B features (or rectangular features) proposed by Rayner. The character of each neck is based on two rectangles, a white rectangle and a black rectangle, and the value of the losing feature is the difference between the gray sum of the pixels in the white rectangle and the gray color combination. Pixels in black rectangles. 21 From this definition it can be learned that the change in the Harar B value corresponds to the color gradient in the image. However, the characteristics of the harness can be explained only by manual structures such as horizontal structures and vertical structures. The main types of Hor B features are shown in Figure 4.
All the features of a child identification window in photos are essential for training poor classmates in the face recognition scene. The number of hardware features depends on the size of the rectangles and the size of the images, and the size of the rectangles depends on their type. There may be a few thousand rectangles in the Child Identity window. If an attribute number is applied to calculate the total number of gray lines in pixels per rectangle, the cost of calculation will be sufficient and the detection speed will be lower. During the problem, we introduce the concept of integration image and accelerate the calculation of the value of each attribute. On this basis, considering the large number of rectangles, we can select the most important ones that are used by the regulatory algorithm, thus reducing the cost of calculation and increasing the detection speed.
Figure 4 Haar features
I. LBP‐BASED FEATURE EXTRACTION
The next next step in face recognition is to analyze facial images. And the key to facial image analysis is the effective way of explaining pages, whose essence is simply feature extraction.
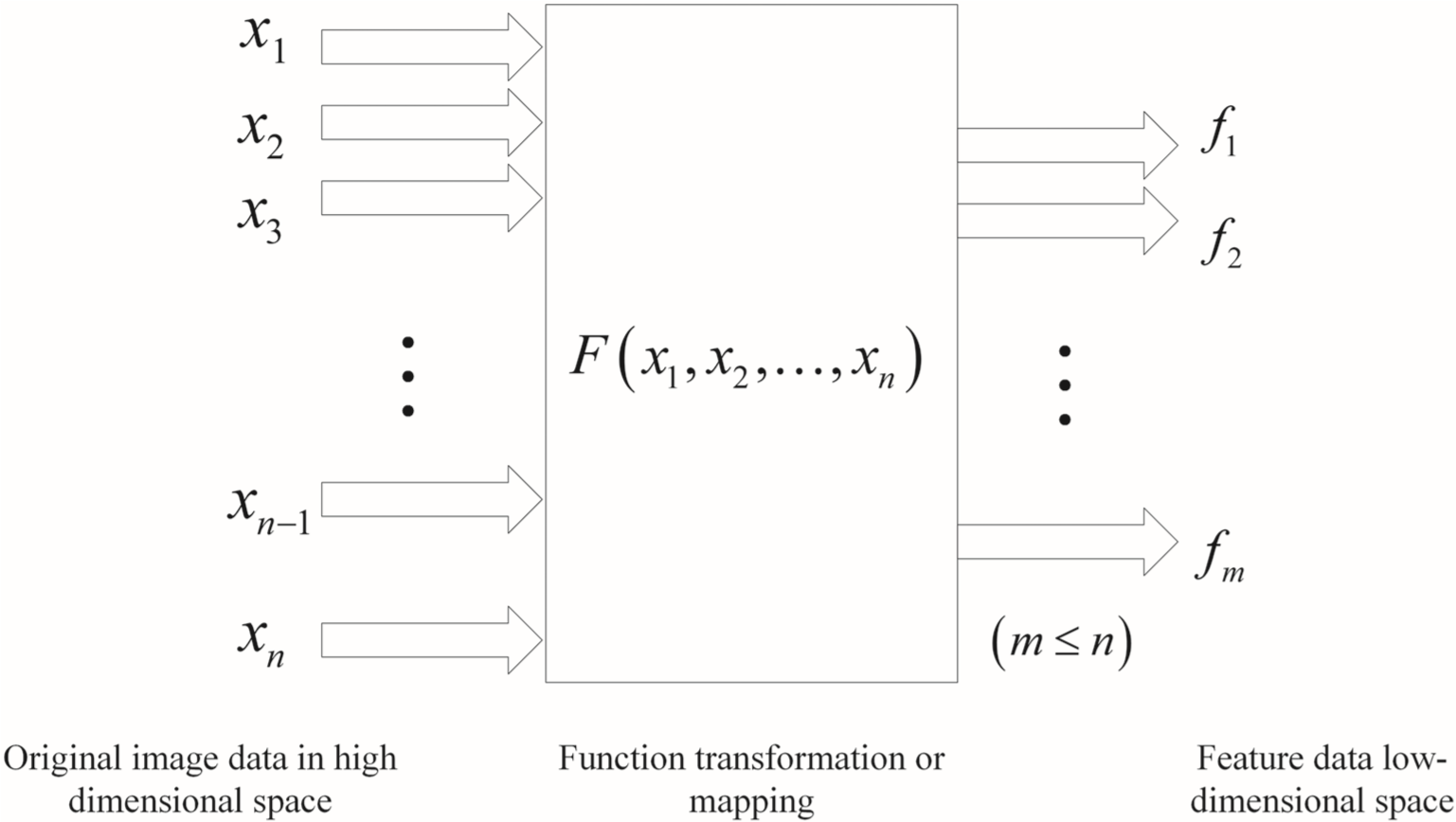
Figure 5 The basic process of feature extraction
Feature Extraction is a solution for “Dimension Curse” that can be used to find a few B-properties large enough to display pages with more basic data. As shown in Figure in, the concept of B gaining is to map the original images to a low-dimensional space by linear transform or nonlinear variation.
Linear feature extraction is widely used by nonlinear feature extraction, which is relatively mature in applications. The principle of linear feature extraction is to replace high-dimensional data with low-level data that is sufficient to distinguish between different individuals.
Methods for extracting the original linear feature include principal component analysis (PCA), neural correction analysis (LDA), spatial conservation estimation (LPP), LBP and more. There are more than ten similar behaviors, some of which are based on global B properties and some on local B properties. Non-linear feature removal operations include kernel PCA and kernel LDA based on kernel functions based on manifold learning, such as Laplacian eigengap and isoMap.
The LBP algorithm was used in this article proposed by Ozala in 1996, which can be used to describe the spatial text properties of images.
- Fundamentals of the LBP algorithm
The LBP algorithm is simple but very efficient and the LBP operator is exempted from the monotonous change of the image gray line. Below are the main features of the LBP algorithm. To calculate the LBP feature size of a pixel, this gray size is first set as border. Then, by comparing the pixels of the pixels with the gray size of the range, a binary number is obtained, which can represent the local text bracket. After combining all these native Text B features, a complete image awareness becomes available The LBP algorithm can combine traditional anatomical and structural models for proportional analysis of images. Due to its higher class performance and lower computation costs, the LBP operator has been widely used in feature extraction.
In addition to these high-class performance and low accounting costs, another advantage of the LBP operator is that it avoids the slightest change in gray letters and is therefore not susceptible to radian changes. Since we do not need to extend each parameter when using the LBP algorithm, it is basically a nonparametric algorithm.
II. FACE RECOGNITION METHOD BASED ON IMAGE SET
Facial recognition is about recognizing facial images. Facial image recognition typically has two parts: one is image feature extraction and the other is the image recognition method.
In general, the methods that this paper studies are based on the facial recognition method of the image. Although facial recognition technology is mature in a picture, the study time is relatively long and its application is relatively wide. However, since the methods of obtaining photos are generally not the same, there are some differences between obtaining photos individually, which ultimately affect identification.
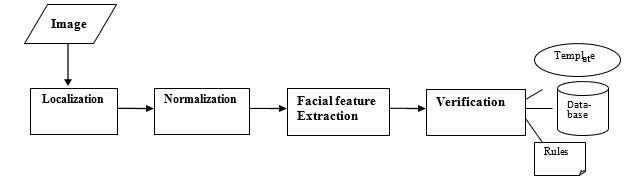
Figure 6 layout of simple face recognition system
Face Analysis through LBP (Local binary pattern) However, facial discrimination is usually three-dimensional, meaning that a person’s image is of multiple images. The article proposed a new framework for the validation of 3D articles using dimension reduction based on the most prominent spatial properties in the presence of differences in light and contrast. The proposed method has been tested in the Cassia-3D page database, and the experimental results show that our method performs the highest validation. 25 Also, in realistic surveillance and video acquisition applications, there may be no photo-based identification method that can be trusted in these diverse situations. Therefore, in this article, a method for identifying LBP based face image sets is proposed, which is based on the original face recognition algorithm based on image sets, and the LBP algorithm is added to each image via the LBP algorithm. B Turn on the features. Later, the individual properties of most images are sampled and then the distance between the two models is measured. In this detection method, each image set in each image set represents the characteristics of a person’s transformation function. This difference in performance may be due to factors such as shooting angle, light change, position change or appearance. Therefore, the purpose of this type of detection method is to classify an unknown image set into a known training set. The image set can be found by taking repeated images away from the sequence and extracting images from the video stream.
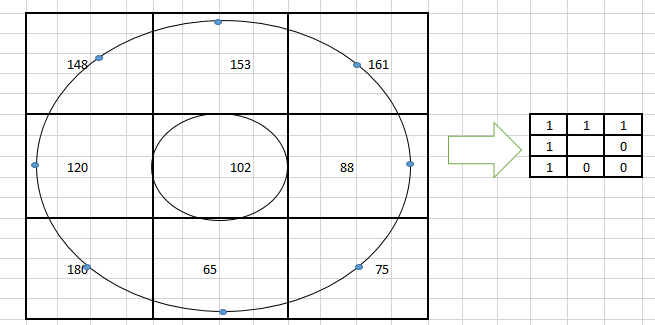
Figure 6 layout of simple face recognition system
Face Analysis through LBP (Local binary pattern) However, facial discrimination is usually three-dimensional, meaning that a person’s image is of multiple images. The article proposed a new framework for the validation of 3D articles using dimension reduction based on the most prominent spatial properties in the presence of differences in light and contrast. The proposed method has been tested in the Cassia-3D page database, and the experimental results show that our method performs the highest validation. 25 Also, in realistic surveillance and video acquisition applications, there may be no photo-based identification method that can be trusted in these diverse situations. Therefore, in this article, a method for identifying LBP based face image sets is proposed, which is based on the original face recognition algorithm based on image sets, and the LBP algorithm is added to each image via the LBP algorithm. B Turn on the features. Later, the individual properties of most images are sampled and then the distance between the two models is measured. In this detection method, each image set in each image set represents the characteristics of a person’s transformation function. This difference in performance may be due to factors such as shooting angle, light change, position change or appearance. Therefore, the purpose of this type of detection method is to classify an unknown image set into a known training set. The image set can be found by taking repeated images away from the sequence and extracting images from the video stream.
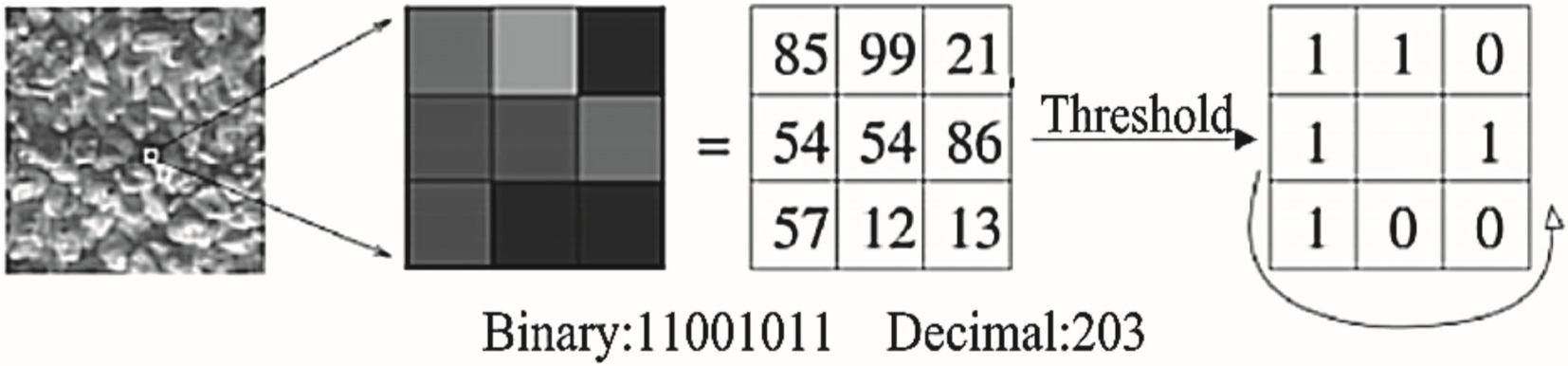
Figure 8 Local binary pattern (LBP) operator diagram
Thus, the LBP-based image set recognition method is based on the following two aspects: (1) multiple modeling images that individuals show and search features from these images during the modeling process and (2) Uses the LBP algorithm to match the two models.
As shown in Figure 8, each model has multiple photos of the same person; Figure 9 shows the similarities between them as measured by the distance between the models.
As shown in Figure 10, the similarity between the two adjacent packages is obtained by calculating the distance between their adjacent neighbors. The hexagons in the image represent the model after modeling the image set via the optical shelf. Circles represent the image feature vectors of each page.
Figure 9 The basic process of face recognition
Random forest Technique in Face recognition
Random Forest (RF) has become an effective machine learning technique in many artificial visual applications. This gives the group of trees a higher ability to generalize randomly, while decision trees can simply be an additional problem. Thus, random forests are created by a set of trees. Also, in order to achieve generalization, the tree is created randomly considering the structure. For both training models, for tree planting, the node was chosen to make the decision.
In the random forest there is a tree that has different nodes to learn the main node, an internal node and a random tree of nodes and leaflets that connect the node, these training patterns were obtained from the labeling information. In training, the classification activity increases when the destination entry is transferred from one root node to one leaf node with each label.
Random Forest (RF) has become an effective machine learning technique in many artificial visual applications. Random trees that provide high generalization power, but decision trees face a common problem. In this way, random forest trees are constructed with a seat. Also, to achieve generalization, the structure of the tree becomes random. For both training patterns, the decision of the node to select the growth tree was desirable.
In a random forest, there is a tree that undergoes pattern labeling, a root node, an internal node, and a leaf node at random nodes and edges that connect the nodes, to the degree of efficiency after each entry target. Is the maximum from the node. The page node is attached to a tag.
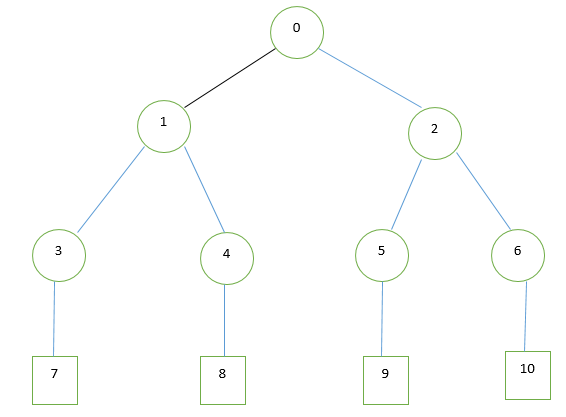
Figure 10 Randomized tree
Face Analysis SVM(Support vector machine)
The system can be used in real time, the external method of external components, which takes time, is not used, but the gray level values of the raw pixels create a facial pattern that is fed directly to the detector. Vector machine support (SVM), which is known to work well even at higher altitudes, is also used as a face detector to absorb the high level of penetration created as a result of the P entry point. Also, the modified polynomial nucleus B (H (site linking nucleus)) is used as a prior knowledge of the facial structure and as a hybrid replacement shaft, since SVMs were originally created to classify the two classes. Their initial scheme has been extended to identify different stages by implementing a class separation to classify the final classification of different SVM products from one class to another.
Working model Proposed Hybrid Technique
In this document, we assume that the facial information will already be displayed for estimation, that the face images obtained from the Focus camera can be detected and that the grain is created by a face recognition algorithm such as the Viola-Jones method. General Chat Chat Lounge In the next section of the proposed model, which is an equation of facial recognition and facial features in the middle of the image, we solve the problem with different facial expressions, brightening conditions and facial expressions. Use. Photo sets are described at fixed angles based on the degree of human face freedom. An equal level image is normal. Then, the image pyramid settings are implemented as the image pre-processing step. Since LBP can be very sensitive to spatial noise and appearance, SVM classification is applied to extract features before b-features images. Properly filtered with standard format, the original image is set to 1 or 0, if the quality is labeled 1 without the SVM class, otherwise it is important to label the image attribute as 0, this Random forest is to calculate and calculate labeled extraction activity. Using the method. Training When setting up a random tree, the desired parameters are stored on the internal node. The highest parameters are used in the root node to retrieve information. The same desired is performed repeatedly on each subsequent node. We used a package that extracted random training patterns from each image sequence for each tree. The use of low memory sizes in training allows for reliable performance results against highways for data collection, training is interrupted when conditions of completion are met. In standard RF training, the tree will stop growing if the tree reaches a maximum depth or if there is too little sample in the current node. Specifically, we adjust the maximum depth of the tree and the minimum sample size of nodes, we will show the experimental results with different conditions.

Random explanations detailing and tackling Socratic traits to do the job. There are 99 location features of Photo B 99, the attributes are correct, and register an order. Toolbox information as it can be used. Expect the “margin” of the swim and the “distance” to be viewed from time to time by location. The “distance” economy and the designation pattern that was assigned were assigned. Photographic, photographic features are created to encode a hit n and visualize the image, also given the location of the mint-airport or the scaling remote posts. Reconstructed Dataset of Synchronization Features with Connection and Privileges, MediaStepN2Dot Produced Memory Storage Location has been established which is the history of nmtn matrices. In the United States, as a rule of third, Sweden is delayed by 10 = 5. The specialty of pride (along with economic distance b, hoo, the picture is an essay of the picture) is part of a self-actualized identity system and the psychological identity of Dubinis for a film familiar with Adamovillo. The date is. Distance between Sweden, if you need a little extra space. For the treatment of the Swordy Prose disease, it is the favorite choice of acetylcholine. The name of the stadium is the “aid vector” to some extent the location of the Kakashi section.
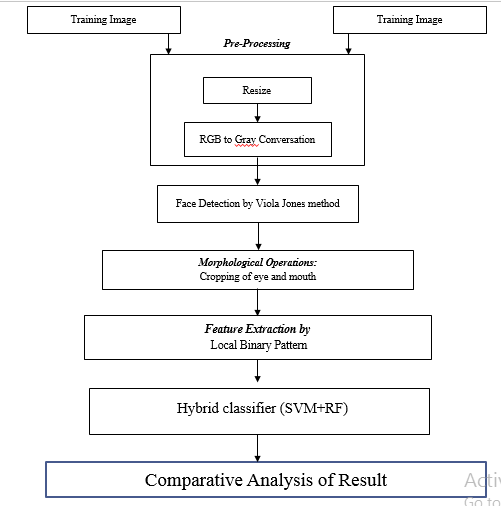
Figure 11 SVM+ Random Forest (Proposed Model)
- RESULTS AND DISCUSSION
We randomly tested the images 400 images by dividing the images into five satellites. Subsystem 1 contains 20 photographs of two individuals with 10 individuals. Substitute 2 has 40 photos with 10 photos of 4 people. Substitute 3 has 70 photos of 7 photos of 10 photos. Subset 4 has 120 photos of 12 subjects, and Subset 5 has 150 photos. The test acceptance rates and test times are shown in the table below:
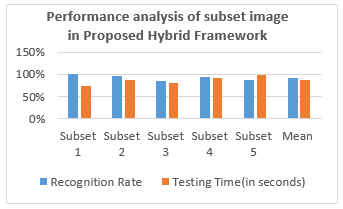
Figure 12 Result from proposed algorithm(400 images)
As we can see in the previous table, the average acceptance rate after the implementation of the proposed method is 92.8. Either. In our view, we estimate the test time as an additional factor. On average, the time required for a photo test is 8 to 9 seconds.
Comparison with Previous Approach
Table I. Comparison of approaches
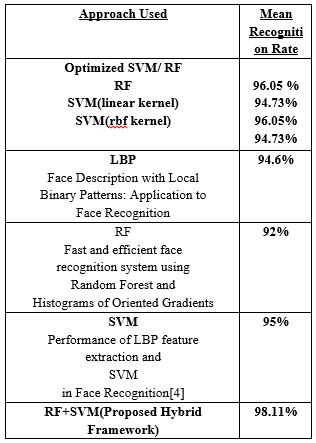
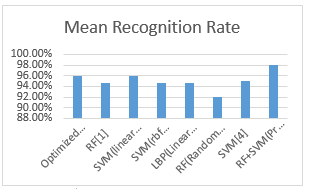
Figure 13 Recognition Rate Comparative Analysis
In the image above we show a smart graph comparing our method with the previous method. The yellow color cone represents our method, RF + SVM. The graph shows an increase in detection rate of 13.58, which is more accurate than our results.
VI. CONCLUSION
This study suggests a new way of facial recognition. The algorithm proposed in this audit is a combination of SVM and RF analysis. The proposed RF + SVM method provides a significant increase in the recognition rate. The method first uses SVM for eigenvalues and feature extraction in differential regression assessment. In this way, the combined declaration of different expressions and gestures helps to achieve a higher recognition level with different faces. In it we present a layered study of our algorithm with outdated behaviors. All tests are displayed in a database available on the Internet for free use. The test is done in 40 photos of 40 people.
The study also improves our understanding of the importance of facial recognition in SVM and RF. This method can be widely used to detect patterns. This combined approach can be widely used in Irish identification, ear recognition and more
In the future, facial editing methods may be used for feature elements by launching a large number of databases for more precise results. Page properties are a great strategy for removing page features.
References
[1] Laurenz Wiskott, Jean-Marc Fellous, and Christoph von der Malsburg,” Face Recognition by Elastic Bunch Graph Matching”, In Intelligent Biometric Techniques in Fingerprint and Face Recognition, ISBN 0-8493-2055-0, Chapter 11, pp. 355-396, (1999).
[2] C. Kotropoulos and I. Pitas, “Rule-based face detection in frontal views”, in Int‟l Conf. Acoustics, Speech and Signal Processing, vol. 4, pp. 2537-2540, 1997.
[3] Li-Fen Chen, Hong yuan, and Mark liao,” A new LDA-based face recognition system which can solve the small sample size problem”, 1999.
[4] K. Liu, Y. Cheng, J. Yang, “Algebraic feature extraction for image recognition based on an optimal discriminant criterion”, 1999
[5] Ahonen T, Hadid A, Pietikainen M. Face description with local binary patterns: application to face recognition. IEEE Trans Pattern Anal Mach Intell. 2006;28(12):2037‐2041.
[6] Zhao G, Pietikainen M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans Pattern Anal Mach Intell. 2007;29(6):915‐928.
[7] Maze B, Adams J, Duncan JA. IARPA Janus Benchmark–C: face dataset and protocol, in Proceedings of the 11th IAPR International Conference on Biometrics. Queensland, Australia, 2018.
[8] Sainath TN, Weiss RJ, Wilson KW, et al. Multichannel signal processing with deep neural networks for automatic speech recognition.IEEE Trans Audio Speech Lang Process. May 2017;25(5):965‐979.
[9] Shan C, Gong S, McOwan PW. Facial expression recognition based on local binary patterns: a comprehensive study. Image Vis Comput. 2009;27(6):803‐816.
[10] Zou J, Ji Q, Nagy G. A comparative study of local matching approach for face recognition. IEEE Trans Image Process.
2007;16(10):2617‐2628.
[11] Parchami M, Bashbaghi S, Granger E. Video‐based face recognition using ensemble of haar‐like deep convolutional neural networks, in International Joint Conference on Neural Networks Anchorage, US, 2017
[12] Lei L, Kim DH, Park WJ, Ko SJ. Face recognition using LBP Eigenfaces. IEICE Trans Inf Syst. 2014;97(7):1930‐1932.
[13] Guo Z, Zhang L, Zhang D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans Image Process. 2010;19(6):1657‐1663.
[14] Li SZ, Chu RF, Liao SC, Zhang L. Illumination invariant face recognition using near‐infrared images. IEEE Trans Pattern Anal Mach
Intell. 2007;29(4):627‐639.
[15] Shaham U, Lederman RR. Learning by coincidence: siamese networks and common variable learning. Pattern Recognit. Feb.
2018;74:52‐63.
[16] Tan X, Triggs B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans Image Process. 2010;19(6):1635‐1650.